TensorRT+CUDA加速人体关键点检测
TensorRT+CUDA加速人体关键点检测
目录
1、 人体关键点检测简介
在影视游戏领域中,动画和角色中必须要有动作如奔跑、打斗、跳跃等,动捕技术出来之前的做法是动画师手工一帧帧修,此方法非常耗时,且非常考验动画师的经验。动捕技术常使用演员表演某些动作,并将这些动作转化为数字模型的动作,目前比较主流的几种动捕技术有红外动捕(标记点动捕):演员穿着紧身衣,衣服上挂满红外反光点,通过红外相机获取反光点的运动轨迹来记录运动数据;惯性动捕:演员身上穿上各种陀螺仪进行记录运动数据;无标记动捕:不使用紧身衣,直接使用rgb相机获取图像,从图像中提取关节点来记录运动数据。上述几种方法各有优缺点,无标记动捕的优势在于演员不需要穿戴各种设备,能随意运动。



使用无标记动捕中的第一个重要的步骤就是人体关键点检测,通过算法分析计算出图像中人体各关键点的位置。目前coco人体关键点数据集将人体关键点表示为17个关节,分别是鼻子、左右眼,左右耳,左右肩,左右肘,左右腕,左右臀,左右膝,左右脚踝。如下图所示
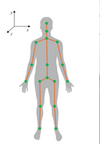
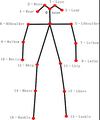
目前主流的是使用深度学习方法计算出人体关键点位置,但是直接使用神经网络训练出的模型进行计算不够快,不能达到实时效果。由于人体关键点检测是整个无标记动捕过程中的第一步,它的效率直接影响整个流程的实时性,而实时是重要的,无论是作为表演时导演观察演员动作是否合理还是作为演员自身对动作细节的把握,都需要实时观察到整个动作的效果。所以得对整个模型进行加速,一种简单的做法是直接增加显卡的数量和计算能力,但此方法得耗费巨大资源购买显卡。另一种方法则是在软件层面上加速算法处理速度。可以使用了TensorRT和CUDA对整个运算过程进行加速,而这两种方法都是在GPU上进行运算,我们先来看看GPU和CPU有什么不同。
2、 CPU和GPU的异同
GPU是graphics procession unit 的缩写,意味图形处理器,与之对应的一个概念是CPU,即center procession unit(中央处理器),一块典型的CPU拥有少数几个快速的计算核心,而一个典型的GPU拥有几百到几千个不那么快速的计算核心,如下图,黄色是控制器,绿色是算数逻辑单元,橙色是存储器,CPU和GPU之间通过PCIe总线连接通信。
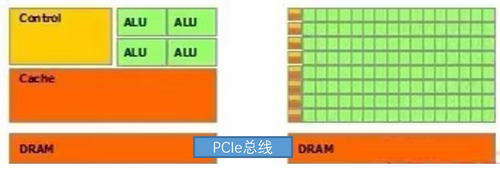
之所以如此设计,是由于其对应于不同的应用场景,CPU需要很强的通用性来处理各种不同的数据类型,同时又要逻辑判断引入大量的分支跳转和中断处理,所以CPU的更多晶体管用于数据缓存和流程控制。而GPU则是用于处理类型高度统一,相互无依存的大规模数据,所以更多的晶体管用于算数逻辑单元。
3、 TensorRT推理加速
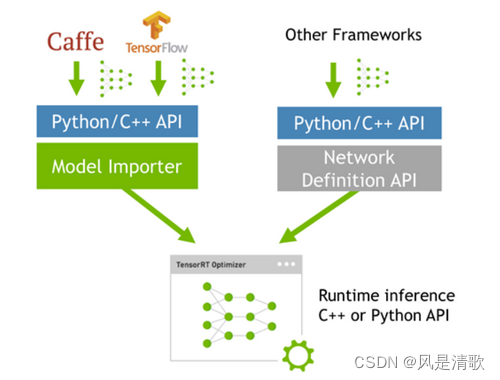
tensorRT是基于python、C++、CUDA编写的一个库,其核心代码为C++和CUDA,用于优化经过训练的的深度学习模型以实现高性能推理。具体流程是将训练好的网络直接扔到tensorRT中,不再依赖深度学习框架(caffe、TensorFlow、pytorch等),如下图所示:
tensorRT的性能优化主要有以下方面:
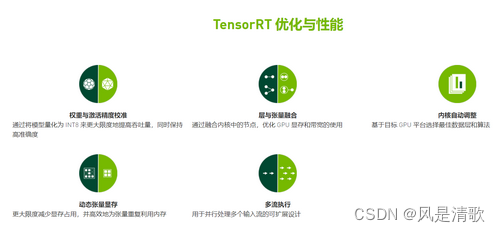
权重激活与精度校准:大部分深度学习框架在训练神经网络时网络中的张量都是32位浮点型的,一旦网络训练完成,在部署推理的过程中不需要反向传播,完全可以适当降低数据的精度(如降低到INT8,相比于float32内存减少为1/4),从而提高整体推理速度。虽说降低了数据的精度可能会导致推理结果出现偏差,但是只谈读毒性不谈剂量都是耍流氓,从实际测试中看int8和float差距并不大,可以满足大多数使用。
层与张量融合:制约计算速度的CUDA核心计算张量,往往大量的时间也是浪费在CUDA核心的启动和对每一层输入/输出张量的读写操作上面,这造成了内存带宽的瓶颈和GPU资源的浪费。TensorRT通过对层间的横向或纵向合并,使得层的数量大大减少,这样就可以一定程度的减少kernel launches和内存读写。
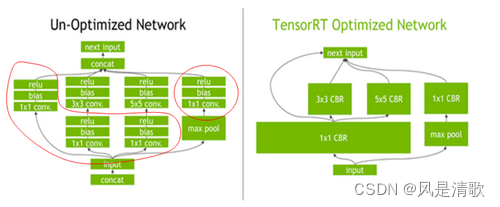
横向合并可以把卷积、偏置和激活层合并成一个CBR结构,只占用一个CUDA核心,纵向合并可以把结构相同但权值不同的层和并成一个更宽的层,也只占用一个CUDA核心,对于多分支合并情况,tensorRT完全可以实现直接到需要的地方,不做专门的concat处理,所以这一层也可以取消掉,合并之后如上图中的右边结构,层次更少、占用的CUDA的核心数也更少,因此整个模型结构会更小更快。
内核自动调整:根据不同的显卡结构、计算单元数量、内核频率等选择不同的优化策略以及计算方式,寻找最合适当前架构的计算方式,这种优化方法也带来了一定的缺点,经过优化的模型和GPU已经产生了绑定,在不同的GPU上优化的模型并不能兼容,但瑕不掩瑜,一般来说在动捕中整个框架都是事先确认好的,而额外增加或者跟换显卡设备也可以快速的从新推理生成模型。
动态张量显存:显存的开辟和释放比较耗时,tensorRT通过一些策略减少显存的开辟和释放次数,增加显存重复利用率从而减少时间。
多流执行:使用CUDA中的stream操作,可以并行处理数据,从而提高显卡的利用率。
通过将训练好的模型进行tensorRT加速优化,并序列化到磁盘中,使用时通过反序列化即可使用优化后的推理引擎加速。使用tensorRT加速的效果如何,通过对比pytorch和tensorRT,均在1080Ti显卡上执行,在pytorch中的计算时间为55毫秒,使用tensorRT加速后的计算时间为10.5毫秒,速度提高了5.23倍。
4、 CUDA编程加速后处理
通过tensorRT优化加速后整个流程并没有结束。首先来看一下关键点回归ground truth的构建问题,主要有coordinate和heatmap两种。Coordinate直接将关键点的坐标作为网络最后的回归目标,使用coordinate之后则不需要再做后续处理,直接将坐标输出给后续流程,但是coordinate回归的是关键点对于图片的offset,而长距离的offset在实际学习过程中很难回归,会造成较大的误差,且在训练过程中提供的监督信息较少,网络收敛较慢。使用heatmap将每一个坐标用一个概率图来表示,对于图片中每个像素都给定一个概率,表示该点属于对应类别关键点的概率,距离关键点越近的概率越趋近1,否则越趋近0,每一个点都设置了监督信息,收敛较快,且对每个像素都提供了预测能有效提高精度。使用heatmap输出的结果并不是单一的坐标,而是一张图像像,如下图所示,整个图像的宽高和输入尺寸一致,17个关键点则有17个维度,需要从这些图像中提取坐标使用CPU计算非常耗时,现在没有了tensorRT这神器帮我们优化了,那么就得靠自己手撸CUDA代码。

CUDA是NVIDIA公司发布的一种操作GPU计算的硬件和软件架构,下图是CUDA的软件架构,开发应用程序以主机(CPU)为出发点,应用程序可以调用CUDA运行时API、CUDA驱动API以及一些已有的CUDA库。所有这些调用都将利用设备(GPU)的硬件资源。
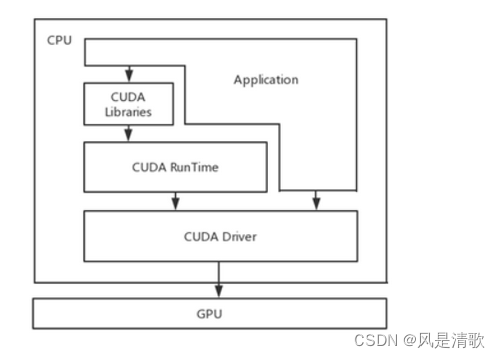
CUDA编程是一个异构模型,不能单独在GPU中运行,必须在和CPU协同工作,在CUDA中有host(CPU及其内存)和device(GPU及其内存)两个重要概念,前面介绍了CPU和GPU的异同,所以对于较多逻辑判断、分支跳转时使用CPU,需要处理大量简单重复的数据使用GPU,并通过PCIe总线进行通信。以处理关键点heatmap为例,第一步需要将heatmap缩放到输入尺寸,具体流程:(1)、得到tensorRT推理之后的数据,由于tensorRT推理后的数据本身就存在显存中,所以不需要再重新复制,直接可以将数据指针传入到处理函数中;(2)、传入之后根据缩放图像大小开辟等量的数据,在cuda中使用<<<grid,block>>>配置线程数。(3)、每个线程单独处理每个像素值计算出当前位置缩放的值,使程序在逻辑上处于并行状态。
上面步骤中grid表示线程块数,block表示每个线程块内的线程数,所以总大小为grid*block个线程, 之所以说在逻辑上是并行的,是由于GPU和CPU类似,多线程如果没有多核支持,在物理层上无法实现并行。但GPU有很多CUDA核心,GPU硬件的一个核心组件是SM(流式多处理器),SM的核心组件包括CUDA核心、共享内存、寄存器等,SM可以并行的执行数百个线程。所以,上述流程被执行时,grid中的线程块被分配到SM上,SM中以线程束作为基本执行单元,目前所以GPU中线程束大小都是32,所以物理上并行的最大线程数为32个线程。
Heatmap经过缩放,非极大值抑制等一系列处理最终输出得到关键点精确坐标,对比CUDA编程和CPU编程,在CPU(i7 3.2GHz)上处理整个过程消耗25毫秒,在CUDA(1080Ti显卡)中处理消耗2.3毫秒,提升超过了10倍。
注。1
本文仅供学习参考,未经允许,拒绝转载或者用作他用。
- 参考连接
https://developer.nvidia.com/zh-cn/tensorrt
https://zhuanlan.zhihu.com/p/102457223
https://zhuanlan.zhihu.com/p/69042249
https://zhuanlan.zhihu.com/p/371663018 ↩︎## 目标